Data structures for string auto-completing (I): sorted list
On March 14, 2022
There's a rather interesting SWE interview question on how you would build a phone keyboard autocomplete. I'm aware that this may seem gatekeeping / irrelevant CS'ey stuff related, but it serves as a good starter for discussing data structures and computational complexity concerns, which, depending on the position, might be a definitely important topic. Note that other forms of the exercise are possible, such as the phone book variant.
If we remove the system design elements - such as cacheing of hits, distribution of data, etc., the requirement is fairly simple: We need a phone keyboard service that holds a word dictionary internally, and exposes the following methods:
InsertNewWord(string name), wich allows you to add new entries to the dictionary.GetSuggestionsFor(string prefix). which will return all words starting by the prefix.
For simplicity's sake, I won't consider neither concurrency issues - such as two threads trying to add a word a the same time - nor persistence, in memory implementation will be enough.
There are primarily two main concerns we should put the focus on:
-
Search performance of matching records: Here we enter into the big O territory. Full data scans are not acceptable; if we're managing the whole english dictionary we're in the 0.5M records range, so we will have to consider using sorted list for searchs or tree-based data structures.
-
Memory footprint of the implementation: More "sophisticated" data structures might add a significant memory overhead; memory pointers of reference types occupy as much as 64 bit if we're using dotnet, so we have to be careful here with the proliferation of objects and their references.
As we will see, there will be trade-offs between both of them depending on our implementation.
Naive Approach - Sorted List
A very simple solution could be loading all the possible words into a List<string> ; in terms of memory this is possible our best bet. Why discard using an array? The memory footprint is a bit smaller indeed; but it has an disadvantage when adding new elements, since it will always require an array clone operation. It's not like that doesn't happen when using the list wrapper; basically the list's internal array is progressively oversized as the elements are added, so the array clone event will happen more sparsely as the number of elements is increased.
When looking for prefixes into the list, in order to avoid transversing it completely and perform a linear search, we will need to have it sorted at any moment, so we can apply sublinear - read O(log n) - search; This actually translates on that anytime a new word is inserted we will need to sort it. This is really inefficent in terms of performance, but it could work if we start with a pre-filled dictionary and the event of adding new words is rare.
Anyway, looking for an exact word is not what we need; we have on one hand the search prefix, and on the other, a list of complete words, so when performing the List's BinarySearch we will need a custom comparer which will leverage string's StartWith(). Then, once we find any element in the list starting with our search prefix, we will scan the list left/right from that position looking for all the matches. Let's see a simple implementation:
public class ListBased
{
private List<string> _data;
public ArrayBased(ICollection<string> entries)
{
_data = new(entries);
_data.Sort(StringComparer.Ordinal);
}
//....
This code snippnet demonstrates object initialization; internal list is populated and then sorted out. Performance is array copy O(n) plus O(n log (n)) for sorting, which is reduced to the latter by the big O sum properties.
public void AddWord(string word)
{
if(_data.BinarySearch(word) < 0) {
_data.Add(word);
_data.Sort(StringComparer.Ordinal);
}
}
In order to add a word, it's important to acknowledge the importance of keeping the list sorted; it's a requirement for the BinarySearch method to work.
Performance is definitely not good; Two steps, one of O(log(n)) to search the word and then O(n log n) for Sort() method, given that internal implementation uses QuickSort algorithm. This leaves us with superlinear O ( n log (n)) performance. So, as already mentioned, using this array-based data structure is very inneficient in these scenarios having lots of new word insertions. For these, we will need to explore the concept of auto-sorted insertions.
public IEnumerable<string> GetSuggestionsFor(string prefix)
{
var results = new List<string>();
var firstMatchPosition = _data.BinarySearch(prefix, new PrefixComparer());
if(firstMatchPosition >= 0)
{
results.Add(_data[firstMatchPosition]);
SearchToTheRight(prefix, results, firstMatchPosition);
SearchToTheLeft(prefix, results, firstMatchPosition);
}
return results;
}
The GetSuggestionsFor(string prefix) implementation starts by finding any word containing the prefix in the array. Note how the custom comparer PrefixComparer is used. Once it's found, it transverses the array in both directions collecting results while there's a StartsWith match. In time complexity terms, the method performs in linear time, O(log n) + O(n) which translates in O(n). Not really efficient, but for long prefixes, the number of positions to scan will be significally smaller than the total.
There's nothing really interesting going on in these SearchToTheXxxx methods:
private void SearchToTheRight(string searchText, List<string> results, int firstMatchPosition)
{
var startingPosition = firstMatchPosition == 0 ? firstMatchPosition : firstMatchPosition + 1;
var keepSearching = true;
while (keepSearching && startingPosition < _data.Count)
{
var currentEntry = _data[startingPosition];
if (currentEntry.StartsWith(searchText, StringComparison.Ordinal))
{
results.Add(_data[startingPosition]);
startingPosition++;
}
else
{
keepSearching = false;
}
}
}
The benchmarks
In order to set a baseline to compare with upcoming implementations, let's load the english dictionary, taken from this github page, and perform queries by a few terms of different lengths. Smaller terms will produce bigger times because longer scan span on both sides of the array:
[MemoryDiagnoser]
public class DictionarySearchTest
{
private string[] _data;
private ListBased _sortedList;
[Params("cl", "clo", "clou", "cloud")]
public string SearchText { get; set; }
[GlobalSetup]
public void Init()
{
_data = File.ReadAllLines($"{Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location)}/words.txt");
_sortedList = new(_data);
}
[Benchmark]
public void SearchRandomWordDictionary()
{
_sortedList.GetSuggestionsFor(SearchText);
}
}
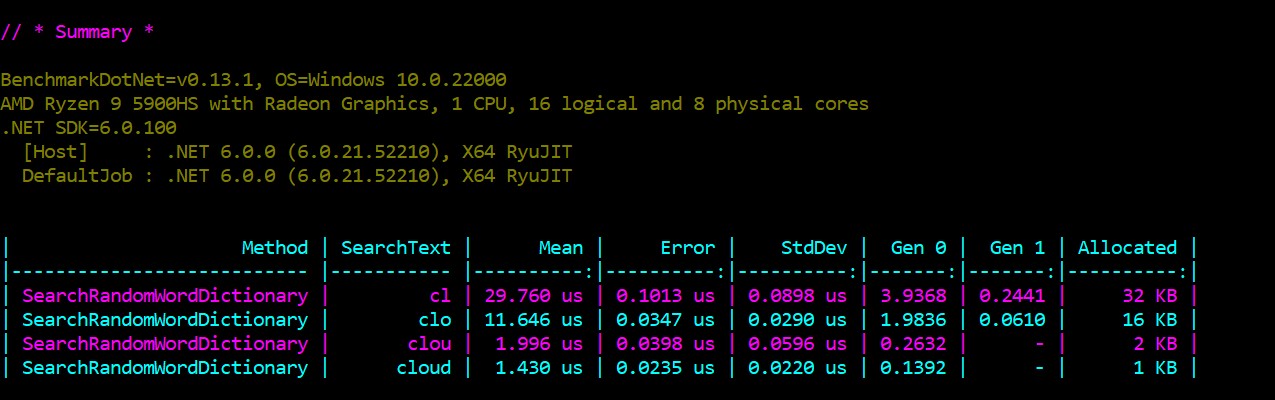
An that's it for this first post in the series. On the next post, we will explore another approach involving tree-like data structures.