Benchmarking persistence of aggregates in RDMS: JSON documents vs classic SQL
On September 13, 2022
Over the last decade, RDBMS vendors have jumped into the JSON / no-sql wagon 1 2, extending their solutions to support persistence and opertations around JSON documents. But, one might wonder how powerful are these features when compared with native no-sql solutions, and to what extent they can be leveraged before considering adding new technology into your stack. It's obvious that specialized solutions will be feature richer than RDMS with respect JSON management - and perhaps with out-of-the-box horizontal scalability capabilities-. Although it's clear that you cannot compare a swiss army knife with a dedicated tool, not every app needs advanced features such as ad-hoc queries, sharding, replication, or load balancing, so it's probably worth it taking a look before adding a new piece into your tech stack.
Having said that, we will try to find an answer to this from the perspective of performance in the context of a single node data store, by executing common operations such as queries and writes. Also, library/tooling maturity concerns will be considered too.
The tech stack
The system under load will be a dotnet 6 application, leveraging EntityFramework 6 plus the awesome NpSQL EF Core Provider library; Databases of choice will be MongoDb and Postgresql; Components will be dockerized, and depending on the testing scenario, resource-limited to either 2 / 0.5 CPU plus 400Mb of RAM. Load tests will be run using K6 as usual.
I've chosen Postgresql since it natively provides column types since version 10 3; besides, the entity framework NpSQL library allows to query documents linq-styled, translating the expression trees into Postgresql jsonb query language, though there are some limitations as we will see. Industry lead MongoDB is used as a baseline to compare Postgresql database JSON management.
The model
The best model to test this is using a tree-like cluster of entities with compositional UML relationships. The canonical blog model will serve us to run the experiments:
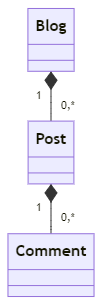
RDBMS configuration is straightforward by using EF, consisting of three levels of nesting:
public class BlogEntityTypeConfiguration : IEntityTypeConfiguration<Blog>
{
public void Configure(EntityTypeBuilder<Blog> builder)
{
builder.HasKey(b => b.BlogId);
builder
.HasMany(b => b.Posts)
.WithOne().
HasForeignKey(b => b.BlogId);
}
}
To get the advantage of Postgres jsonb type, we will create a new table that will act as key-value storage, just like document databases do. The table's key will match the stored blog's key as the following configuration demonstrates:
public class BlogAggregate
{
public Guid Id { get; set; }
public Blog Blog { get; set; }
}
public class BlogAggregateEntityTypeConfiguration : IEntityTypeConfiguration<BlogAggregate>
{
public void Configure(EntityTypeBuilder<BlogAggregate> builder)
{
builder.HasKey(b => b.Id);
builder
.Property(b => b.Blog)
.HasColumnType("jsonb");
}
}
Around 100 blogs with a number of child entities will be created. This way the whole dataset will fit in Postgresql default page cache size.
The tests
The dotnet application will be severly resource-constrained compared to the databases (0.5 CPU vs the 2 CPU). Under high load and contention circumnstances, the response times provide an idea of what operation mode is less CPU demanding - smaller response time under contention, smaller number of CPU operations. Besides this, the growth rate of the datastore CPU utilization on the increasing number of concurrent users will shed some light on what is more expensive to process for the persistence mechanism.
Three tests will be run in each scenario:
- 1 virtual User trying to complete 500 requests;
- 5 concurrent virtual users trying to complete 500 requests each;
- 10 concurrent virtual users trying to complete 500 requests each;
On each run, median request response time, total time spent and average CPU usage at database level will be measured. Dotnet app will be always under 100% as it's being stimulated heavily by k6.
Test #1: Querying by Key
A blog will be served by querying the database by its Id field. This is the fastest possible operation we can perform, assuming an index there. Indeed, we will have a primary key in Blog's Id field and in BlogAggregate's Id. MongoDb automatically creates an index for the document's ObjectId field.
In the relational approach, we will benchmark both with and without AsSplitQuery(). By using it queries retrieving nested relationships data are split avoiding the cartesian product of the different rows hierarchies preventing redundant data to travel over the wire, but this comes at the cost of having more than one database network calls. It will be interesting to evaluate what is the resource impact at the application and database container.
//Regular query, non-splitted
await myDbContext.Blogs.
Include(x => x.Posts).
ThenInclude(x => x.Comments).
FirstAsync(x => x.BlogId == id);
The test consists of X concurrent virtual users per database, each of them trying to complete a number of calls to get a random Blog; Total time spent to complete all the concurrent VU * calls are recorded:
MongoDb outperforms any flavor of Postgresql we use - be JSON or classic relational data - which is no surprise. But, here Postgresql JSON's has a definite edge versus classic relational approach, in the form of a decreased CPU usage and faster times - especially compared with the AsSplitQuery() variant -. Another interesting finding is how much the total time grows as more VU (virtual users) enter; MongoDb grows with a smaller gradient which could be related to the bson deserialization being less resource-intensive than Entity Framework's. By inspecting the docker stats command, in any case, neither postgresl or mongodb containers go beyond 50% CPU / usage; Conversely, dotnet app goes full 100% CPU trying to fulfill all the requests; after all, it's a single CPU container which is quite busy delivering such non-stop traffic.
There's a lot of contention in the non JSON versions of the query as the VU number increase; Indeed, Postgresql CPU decreases as dotnet application gets really busy processing the retrieved aggreagate data, requesting less data from the database.
Test #2: Querying by non-idexed field
Querying by an non-indexed field implies table/document collection scans which obviously are very expensive. What is not so clear is how much less efficient will be for the Postgresql engine to inspect the jsonb field versus start page jumping inspecting the heap's different items at the row data level. In both cases, there shouldn't be a lot of disk I/O since heap pages will be in the cache as they mostly fit in memory. Indeed, following screenshot demonstrates that in the case of the JSON aggregate query - all data is read from the cache since there's no Buffers: shared read number entry in the query plan - :
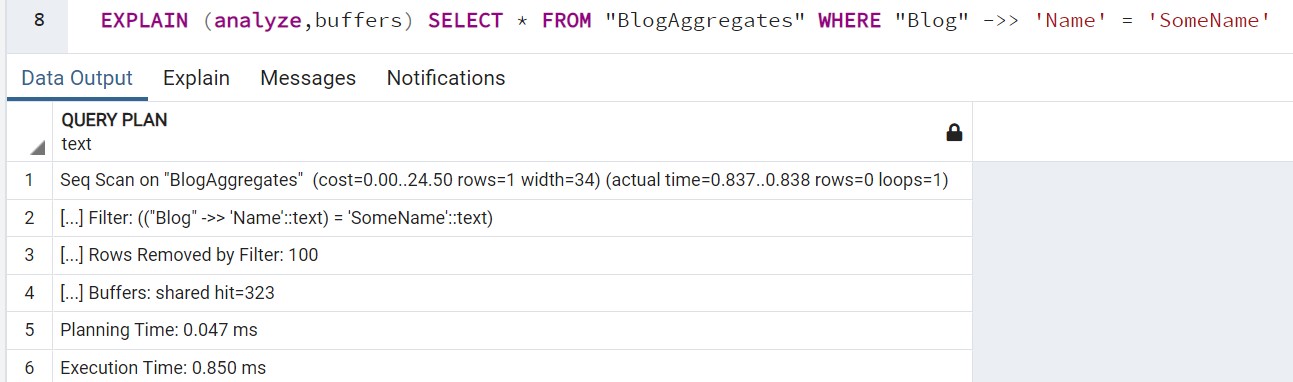
With respect MongoDb, it also caches documents in memory, so scan will be rather fast. Anyway, to ensure such behaviour a cache warm-up run will be executed for all scenarios.
Again, MongoDb is the fastest solution. Interestingly, tests over the JSON column are faster than SQL's, likely because of fastest deserialization at dotnet level. In fact, in terms of query performance, at Postgresql level querying the relational model is about 10x faster compared to inspecting the json column ( 0.065 ms VS 0.873 ms ). CPU numbers already told this story.
Test #3: Updating root entity field
It's no surprise that Json Postgresql is the slowest one here. This is due to EF Posgtresql aggregate updates triggers a whole document replacement which is very inneficient:
var blog = await myDbContext.BlogAggregates.FindAsync(id);
blog!.Blog.Name = newValue;
myDbContext.Entry(blog).Property(e => e.Blog).IsModified = true;
await myDbContext.SaveChangesAsync();
Above code produces the following SQL:
"Message":"Executed DbCommand (1ms) [Parameters=[@p1=\u0027?\u0027 (DbType = Guid), @p0=\u0027?\u0027 (DbType = Object)], CommandType=\u0027Text\u0027, CommandTimeout=\u002730\u0027]\nUPDATE \u0022BlogAggregates\u0022 SET \u0022Blog\u0022 = @p0\nWHERE \u0022Id\u0022 = @p1;"
This could be optimized by using SQL against Postgresql, which would be advisable when executing this kind of operations. An example in Postgresql SQL dialect would be
UPDATE "BlogAggregates" SET "Blog" = JSONB_SET("Blog",'{Name}','"SomeName"') WHERE "Id"977471db-6d30-40e6-a6dd-49927e2cce76'
Mongo, on the other hand, has an specialized API to update only the relevant part of the document:
await mongoBlogs.UpdateOneAsync(Builders<Blog>.Filter.Eq(x => x.BlogId, id), Builders<Blog>.Update.Set(x => x.Name, name));
Conclusions
A few ideas emerged from the above tests, which can be summarized in the following bullet points:
-
Dedicated document store should be first option if expecting to use advanced features or having big throughput/performance requirements. MongoDb noticeably outperforms Postgresql, with a very feature-rich client library.
-
Retrieving a JSON object from Postgresql and deserializing it to a type is less taxing than joining table data and rebuilding. JSON column type works really well for aggregate shaped -data and can be very fast ( up to 33% faster with used data)
-
Though
AsSplitQuery()might be beneficial, performance is way worse than single database roundtrip and comes with bigger database CPU consumption. -
Querying by a non-indexed JSON property taxes heavily on the database; Conversely, the client application consumes fewer resources when creating the object. Indexes on JSON columns can be created anyway.
-
ORM features are limited at this point; To fully leverage JSON columns you will need to use SQL.